

Web安全基础
本文最后更新于 2024-10-15,文章内容距离上一次更新已经过去了很久啦,可能已经过时了,请谨慎参考喵。
title: Web安全基础
tags:
- XSS
- WebSec
categories:
- 网络安全
top_img: false
cover: '/upload/cdn0files/20200721130757.jpg'
abbrlink: 43902f53
date: 2020-02-08 08:19:36
updated: 2020-02-08 08:19:36
Web安全基础
安全问题的本质是信任的问题。
最大的漏洞是人!
在解决安全问题的过程中,不可能一劳永逸,安全是一个持续的过程。
安全三要素
在设计安全方案之前,要正确的、全面的看待安全问题。前辈们经过无数实践,最后将安全的属性总结为安全三要素,简称CIA:
- 机密性 Confidentiality
- 完整性 Integrity
- 可用性 Avaliability
机密性要求保护数据内容不能泄露,加密是实现机密性要求的常见手段。
完整性要求保护数据内容是完整、没有被篡改的。常见的保证一致性的技术手段是数字签名。
可用性要求保护资源是“随需而得”。
在安全领域中最基本的要素就是这三个,后来有人扩充了可审计性和不可抵赖性。
如何实施安全评估
一个安全评估的过程可以简单的分为四个阶段:
- 资产等级划分
- 威胁分析
- 风险分析
- 确认解决方案
如果面对的是一个尚未评估的系统,那么应该从第一个阶段开始实施,如果是由专职的安全团队长期维护的系统,那么有些阶段可以只实施一次。在这几个阶段中,上一个阶段将决定下一个阶段的目标,需要实施到什么程度。
资产等级划分
资产等级划分是所有工作的基础,能帮我们明确目标是什么,需要保护什么。
互联网安全的核心问题就是数据安全的问题。
每个公司对数据的侧重点不同,做资产等级划分的过程需要与各个业务部门的负责人一一沟通,了解公司最重要的资产是什么,为后续的安全评估过程指明方向。
当完成资产等级划分之后,接下来就是要划分信任域和信任边界了。通常会使用一种最简单的划分方式,就是从网络逻辑上划分,比如最重要的数据放在数据库里,那就把数据库的服务器圈起来,Web应用可以从数据库中读写数据并对外提供服务,那就再把Web服务器圈起来,最外面就是不可信任的Internet。
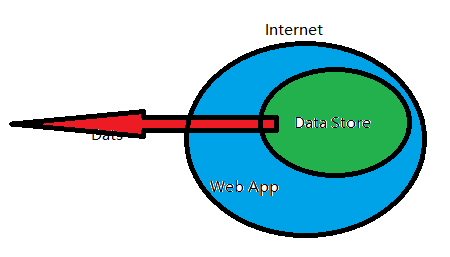
这只是最简单的例子,实际中会遇到比这复杂很多的案例,比如同样是两个应用,互相之间存在数据交互,那么就要考虑到这里的数据交互对于各自应用来说是否可靠,应该在两个应用之间划一道边界,然后对流经边界的数据进行检查。
威胁分析
信任域规划好之后,就要确定危险的来源。我们把可能造成危害的来源叫做威胁(Threat),而把可能出现的损失成为风险(Risk)。风险一定是和损失联系在一起的,又分为两个阶段:威胁建模和风险分析。
最早由微软提出一种模型叫做STRIDE模型,分别是一下六个方面:
| 威胁 | 定义 | 对应的安全属性 |
|---|---|---|
| Spoofing(伪装) | 冒充他人身份 | 认证 |
| Tampering(篡改) | 修改数据或代码 | 完整性 |
| Repudiation(抵赖) | 否认做过的事情 | 不可抵赖性 |
| InformationDisclosure(信息泄露) | 机密信息泄露 | 机密性 |
| Denial of Service(拒绝服务) | 拒绝服务 | 可用性 |
| Elevation of Privilege(提升权限) | 未经授权获得许可 | 授权 |
在进行威胁分析时,要尽可能的不漏掉威胁,头脑风暴的过程可以确定攻击面(AttackSurface)。
漏洞的定义是:系统中可能被威胁利用以造成危害的地方。
在维护安全的过程中,攻击者往往就是利用事先完全没有想到的漏洞完成了入侵,这就是在确定攻击面时想的不够周全。
风险分析
风险由以下因素组成:
Risk = Probability * Damage Potential
影响风险高低的因素,除了造成损失的大小以外,还要考虑到发生的可能性。
举个例子来说,地震造成的损失无法估量,但是发生地震的概率非常小,但是如果是在四川这种地震频发的位置,那就不得不提高这种风险的预警。
科学的衡量风险,有一个DREAD模型,也是由微软提出的:
| 等级 | 高(3) | 中(2) | 低(1) |
|---|---|---|---|
| DamagePotential | 获取完全验证权限;执行管理员操作;非法上传文件 | 泄露敏感信息 | 泄露其他信息 |
| Reproducibility | 攻击者可以随意再次攻击 | 攻击者可以重复攻击,但有时间限制 | 攻击者很难重复攻击过程 |
| Exploitability | 初学者在短期内能掌握攻击方法 | 熟练的攻击者才能完成这次攻击 | 漏洞利用条件非常苛刻 |
| Affected users | 所有用户,默认配置,关键用户 | 部分用户,非默认配置 | 极少数用户,匿名用户 |
| Discoverability | 漏洞很显眼,攻击条件很容易获得 | 在私有区域,部分人能看到,需要深入挖掘漏洞 | 发现该漏洞极其困难 |
在这个模型里,每一个因素都有高、中、低三个等级,每一个等级的3、2、1代表其权重值,因此我们可以具体的计算出某一个威胁的风险值。
比如,从正面进攻:
Risk = D(3) + R(3) + E(3) + A(3) + D(3) = 3+3+3+3+3 = 15
绕一些小路:
Risk = D(3) + R(1) + E(1) + A(3) + D(1) = 3+1+1+3+1 = 9
所以把风险高低定义如下:
- 高危:12~15分
- 中危:8~11分
- 低危:0~7分
但是在任何时候都应该记住,模型是死的人是活的,再好的模型也是需要人来用的,模型只是起到一个辅助的作用,最终做决策的还是人。
设计安全方案
安全评估的产出物就是安全解决方案,解决方案一定要有针对性,这种针对性是由等级划分、威胁分析、风险分析等阶段的结果给出的。
好的安全产品或模块除了要兼顾用户体验外,还要易于持续改进。一个好的安全模块,同时也应该是一个优秀的程序,从设计上也需要做到高聚合、低耦合、易于扩展。
最终一个优秀的安全方案应该具备以下特点:
- 能够有效解决问题
- 用户体验好
- 高性能
- 低耦合
- 易于扩展和升级
白帽子技巧
Secure By Default 原则
黑名单、白名单
例如在制定防火墙的网络访问控制策略时,如果只提供web服务,那么正确的做法是只允许网站服务器的80和443端口对外提供服务,屏蔽除此之外的其他端口,这就是一种典型的白名单做法。
如果上个例子使用的是黑名单规则,就可能出现问题,比如服务器不允许SSH连接,那么就会审计SSH的默认端口22,关闭其对Internet的开放,但是有些工程师为了偷懒或者图方便,会把端口改为2222或者其他,从而绕过安全策略。
最小权限原则
最小权限原则也是安全设计的基本原则之一。最小权限原则要求系统只授予主题必要的权限,不要过度授权。
最生动的例子就是Linux运维工程师都知道,最良好的操作习惯就是使用普通用户登录,而需要使用root权限时再使用sudo命令来完成。
纵深防御原则
Defense in Depth(纵深防御) 也是设计安全方案时的重要思想。
纵深防御包含两层含义:首先,要在各个不同层面、不同方面实施安全方案,避免出现疏漏,不同安全方案之间需要相互配合,构成一个整体;其次,在解决根本问题的地方实施针对性的安全方案。
纵深防御并不是同一个安全方案要做多遍,而是要从不同层面、不同角度做出整体的解决方案。
常见的入侵案例中,大多数是利用web应用的漏洞攻击者先获得一个低权限的webshell然后通过低权限的webshell上传更多的文件,并尝试执行更高权限的系统命令,尝试在服务器上提升权限为root,接下来攻击者就会尝试再进一步渗透内网,比如数据库所在的网段。
在这类案例中,如果能在攻击过程中的任何一个环节设置有效的防范措施,都有可能会导致攻击过程功亏一篑。
就入侵的防御来说,需要考虑的可能有web应用安全、os系统安全、数据库安全、网络环境安全等。在这些不同的层面设计的安全方案,组成整个安全体系,这就是纵深防御的思想。
纵深防御的第二层含义,就是在对的地方做对的事。
举个例子就是XSS防御技术的发展,最初的时候只是过滤掉一些特殊字符,但是这种做法常常会改变用户原本想表达的意思。过滤用户输入并不合适,XSS真正产生危害的场景是在用户的浏览器上,或者说服务器输出的HTML页面,被注入了恶意代码。所以必须把防御方案放到最合适的地方去解决。
数据与代码分离原则
这一原则广泛用于各种由于“注入”而引发的安全问题。实际上缓冲区溢出,程序在栈或者堆中,将用户数据当做代码执行,混淆了代码与数据的边界,就会导致安全问题的发生。
在web安全中,由于注入引起的问题有:XSS、SQL Injection、CRLF Injection、X-Path Injection等。
以XSS为例,它产生的原因是HTML Injection或者JavaScript injection,举个例子:
<html>
<head>
test
</head>
<body>
$var
</body>
</html>
其中$var 就是用户控制的变量,那么对于这段代码来说:
<html>
<head>
test
</head>
<body>
</body>
</html>
就是程序的代码执行片段而$var 就是程序的用户数据片段。如果把用户数据$var 当做代码片段来执行,就会引发安全问题,比如如果$var 的值是:
<script src="http://evil"></script>
用户数据就会被注入到代码片段中,解析脚本并执行的过程,是由浏览器来完成的,浏览器将用户数据里的<script> 标签当做代码来解释。
根据数据与代码分离原则,在这里应该对用户数据片段$var 进行安全处理,可以使用过滤,编码等手段,把可能造成代码混淆的用户数据清理掉。
不可预测性原则
Secure By Default是总则,纵深防御是更全面、更正确的看待问题,数据与代码分离是从漏洞成因上看问题,而不可预测性原则是从克服攻击方法的角度看待问题。
微软应对缓冲区溢出攻击的思路,使用DEP来保证堆栈不可执行,使用ASLR让进程的栈基址随机变化,从而使攻击程序无法准确的猜到内存地址,有一定的随机性,对于攻击者来说就是不可预测性。
不可预测性(Unpredictable)能有效地对抗基于篡改、伪造的攻击。
不可预测性原则可以巧妙的运用在一些敏感数据上,比如在CSRF的防御技术中,通常会使用一个token来进行有效防御,token能成功防御CSRF就是因为攻击者在实施CSRF攻击过程中,是无法提前预知这个token值的。
不可预测性的实现往往需要用到加密算法、随机数算法、哈希算法等。
安全是一门朴素的学问,也是一种平衡的艺术。
浏览器安全
同源策略
浏览器的同源策略,限制了来自不同源的“document”或者脚本,对当前”document”读取或设置某些属性。
a.com的一段JavaScript脚本,在b.com未曾加载此脚本时,也可以随意涂改b.com的页面(在浏览器里的显示),为了不让浏览器的页面行为发生混乱,浏览器提出了“Origin”源的概念,来自不同源的对象无法互相干扰。例如:
| URL | Outcome | Reason |
|---|---|---|
| http://store.company.com/dir2/other.html | Success | |
| http://store.company.com/dir/inner/another.html | Success | |
| https://store.company.com/secure.html | Faiure | Different protocol |
| http://store.company.com:81/dir/etc.html | Faiure | Different port |
| http://news.company.com/dir/other.html | Faiure | Different host |
上表就是浏览器中JavaScript的同源策略,当JavaScript被浏览器认为来自不同源时,请求被拒绝。影响源的因素有:host(域名或IP地址,如果是IP地址则看做一个根域名)、子域名、端口、协议。
需要注意的是,对于当前页面来说,页面内存放JavaScript文件的域并不重要,重要的事加载JavaScript页面所在的域是什么。换句话来说,a.com可以通过以下代码:
<script src="http://b.com/b.js"></script>
加载了b.com上的b.js,但是b.js是运行在a.com页面中的,因此对当前打开的页面(a.com)来说,b.js的源就应该是a.com而非b.com。
在浏览器中,<script 、<img> 、<iframe> 、<link>等标签都可以跨域加载资源,而不受同源策略的限制。
这些带src 属性的标签每次加载时,实际上就是由浏览器发起了一次GET请求,不同于XMLHttpRequest的是,通过src 的属性加载的资源,浏览器限制了JavaScript的权限,使其不能读、写返回的内容。
随着互联网的发展,跨域请求越来越迫切,因此W3C制定了XMLHttpRequest跨域访问标准,它需要通过目标返回的HTTP头来授权是否允许跨域访问,但是这一切都是建立在“JavaScript无法控制该HTTP头”,如果这个规则被打破,这个方案也再不安全。
以Flash为例,它主要通过目标网站提供的crossdomain.xml文件判断是否允许当前源的flash跨域访问目标资源。
浏览器沙箱
在网页中插入一段恶意代码,利用浏览器漏洞执行任意代码的攻击方式,在黑客圈子被形象的成为“挂马”。比如在Windows系统中,浏览器密切结合DEP、ASLR、SafeSEH等操作系统提供的保护技术,对抗内存攻击,与此同时浏览器还发展出了多进程架构,从安全性上有了很大保证。
Google Chrome是第一个采取多进程架构的浏览器。主要分为浏览器进程、渲染进程、插件进程、扩展进程。插件进程如flash、Java、PDF等于浏览器严格隔离,不互相影响。
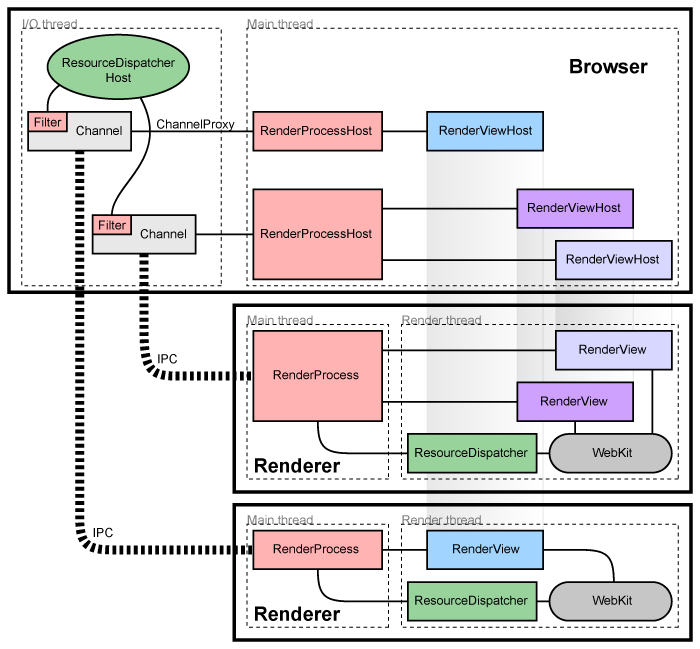
渲染引擎由sandbox隔离,网页代码要与浏览器内核进程通信、于操作系统通信都需要通过IPC channel,其中会进行一些安全检查。
sandbox即沙箱,现在泛指资源隔离模块。它的设计目的一般是为了让不可信任的代码运行在一定的环境中,限制不可信任的代码访问隔离区之外的资源。
恶意网站拦截
目前来说,各个浏览器的拦截恶意网址的功能都是基于黑名单规则的,工作原理很简单,一般都是浏览器周期性的从服务器端获取一份最新的恶意网址名单,如果用户访问就会拦截警告。
常见的恶意网址分为两类,一类是挂马网站,这些网站通常包含有恶意的脚本如JavaScript或者Flash,通过利用浏览器的漏洞执行shellcode,在用户电脑中植入木马,另一类是钓鱼网站,通过模仿知名网站的相似页面来欺骗用户。
要识别这两种网址,需要建立很多基于页面特征的模型,而这些模型显然是不适合放在客户端的,因为会让攻击者分析研究并绕过这些规则。同时对于收集用户浏览历史是一种侵犯隐私权的行为。
基于这两种原因,浏览器厂商目前只是以推送恶意网站黑名单为主,一般而言,浏览器厂商选择与专业的安全厂商或机构合作,由他们定期提供黑名单。
除了黑名单拦截功能之外,现在也有EV SSL证书以增强对安全网站的识别。这个证书是全球数字证书颁发机构与浏览器厂商一起打造的增强型证书,其主要特色是浏览器会给予EVSSL证书特殊待遇。
现在的浏览器飞速发展,更完备的安全性能,更丰富的功能和扩展,同时也带来了更大的挑战。
跨站脚本攻击XSS
XSS简介
跨站脚本攻击,英文全称是Cross Site Script本来缩写是CSS,但是为了和层叠样式表(Casading Style Sheet)区别,所以在安全领域叫做XSS。
XSS攻击通常指黑客通过“HTML注入“篡改了网页,插入恶意的脚本从而在用户浏览网页的时候,控制用户浏览器的一种攻击方式。
XSS长期以来被列为客户端Web安全的头号大敌。因为XSS破坏力强大且产生的场景复杂,难以一次性解决,业内达成的共识是:针对各种不同场景产生的XSS,需要区分情景对待,即便如此,复杂的应用环境仍然是XSS滋生的温床。
那么到底什么是XSS呢?举一个具体的例子:
假设一个页面把用户输入的参数直接输入在页面上:
<?php
$input = $_GET["param"];
echo "<div>".$input."</div>";
?>
在正常情况下用户向param提交的数据会展示到页面中,例如:
http://192.168.1.43/test.php?parm=测试
结果如下:

网页的源代码可以看到:
<div>
测试
</div>
如果要是提交一段HTML代码呢:
http://192.168.1.43/test.php?param=<script>alert(/XSS/)</script>
结果: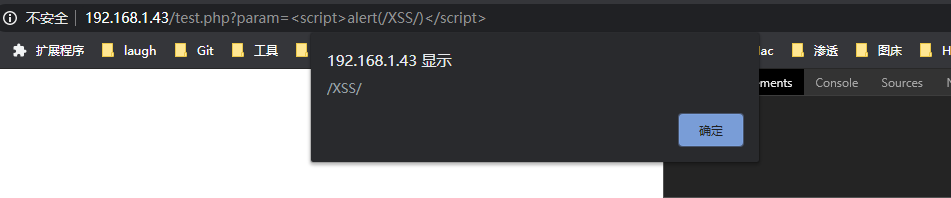
代码被成功执行,网页源代码中也被插入了脚本的代码。
这就是XSS的第一种类型:反射型XSS
XSS按照效果的不同可以分为以下几类:
- 反射型XSS:只是简单的把用户输入的数据“反射”给浏览器,也就是说黑客往往需要诱导用户“点击”一个恶意链接才能攻击成功,所以也叫“非持久型XSS”(Non-persistent XSS)
- 存储型XSS:存储型XSS会把用户输入的数据“存储”在服务器端,具有很强的稳定性。也叫“持久性XSS”(Persistent XSS)
- DOM Based XSS:从效果上来说也是反射型XSS,单独提出来是因为它的形成原因比较特殊复杂。
通过修改页面DOM节点形成的XSS,称之为DOM Based XSS,举个例子:
<script>
function test() {
var str = document.getElementById("test").value;
document.getElementById("t").innerHTML = "<a href=' "+str+" ' >testLink</a>";
}
</script>
<div id="t">
</div>
<input type="text" id="text" value=""/>
<input type="button" id="s" value="write" onclick="test()" />